What is DKIM?
DKIM (DomainKeys Identified
Mail), as
Wikipedia puts it, "is an email authentication method designed to
detect forged sender addresses in emails (email spoofing), a technique
often used in phishing and email spam". More prosaically, one of the
reasons email spam is so abundant is that, given a certain email
message, there is no simple way to know for certain who sent it and
how reputable they are. So even if people having addresses
@debian.org are very nice and well-behaving, any random spammer can
easily send emails from
whatever@debian.org, and even if you trust
people from
@debian.org you cannot easily configure your antispam
filter to just accept all emails from
@debian.org, because spammers
would get in too.
Since nearly ten years DKIM is there to help you. If you send an email
from
@debian.org with DKIM, it will have a header like this:
DKIM-Signature: v=1; a=rsa-sha256; c=simple/simple; d=debian.org;
s=vps.gio.user; t=1586779391;
bh=B6tckJy2cynGjNRdm3lhFDrp0tD7fF8hS4x0FCfLADo=;
h=From:Subject:To:Date:From;
b=H4EDlATxVm7XNqPy2x7IqCchBUz1SxFtUSstB23BAsdyTKJIohM0O4RRWhrQX+pqE
prPVhzcfNALMwlfExNE69940Q6pMCuYsoxNQjU7Jl/UX1q6PGqdVSO+mKv/aEI+N49
vvYNgPJNLaAFnYqbWCPI8mNskLHLe2VFYjSjE4GJFOxl9o2Gpe9f5035FYPJ/hnqBF
XPnZq7Osd9UtBrBq8agEooTCZHbNFSyiXdS0qp1ts7HAo/rfrBfbQSk39fOOQ5GbjV
6FehkN4GAXFNoFnjfmjrVDJC6hvA8m0tJHbmZrNQS0ljG/SyffW4OTlzFzu4jOmDNi
UHLnEgT07eucw==
The field
d=debian.org is the domain this email claims to be from
and the fields
bh= and
b= are a cryptographic public key signature
certifying this fact. How do I check that the email is actually from
@debian.org? I use the selector
s=vps.gio.user to fetch the public
key via DNS, and then use the public key to verify the signature.
$ host -t TXT vps.gio.user._domainkey.debian.org
vps.gio.user._domainkey.debian.org descriptive text "v=DKIM1; k=rsa; s=email; h=sha256; p=" "MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAsM/W/kxtKWT58Eak0cfm/ntvurfbkkvugrG2jfvSMnHHkFyfJ34Xvn/HhQPLwX1QsjhuLV+tW+BQtxY7jxSABCee6nHQRBrpDej1t86ubw3CSrxcg1mzJI5BbL8un0cwYoBtUvhCYAZKarv1W2otCGs43L0s" "GtEqqtmYN/hIVVm4FcqeYS1cYrZxDsjPzCEocpYBhqHh1MTeUEddVmPHKZswzvllaWF0mgIXrfDNAE0LiX39aFKWtgvflrYFKiL4hCDnBcP2Mr71TVblfDY0wEdAEbGEJqHR1SxvWyn0UU1ZL4vTcylB/KJuV2gMhznOjbnQ6cjAhr2JYpweTYzz3wIDAQAB"
There it is! Debian declares in its DNS record that that key is
authorized to sign outbound email from
@debian.org. The spammer
hopefully does not have access to Debian's DKIM keys, and they cannot
sign emails.
Many large and small email services have already deployed DKIM since
years, while most
@debian.org emails still do not use it. Why not?
Because people send
@debian.org emails from many different
servers. Basically, every DD used their
@debian.org address sends
email from their own mail server, and those mail servers (fortunately)
do not have access to Debian's DNS record to install their DKIM
keys. Well, that was true until yesterday! :-)
A few weeks ago I poked DSA asking to allow any Debian Developer to
install their DKIM keys, so that DDs could use DKIM to sign their
emails and hopefully reduce the amount of spam sent from
@debian.org. They have done it (thank you DSA very much, especially
adsb), and now it is possible to use it!
How do I configure it?
I will not write here a full DKIM tutorial, there are
many
around. You
have to use
opendkim-genkey to generate a key and then configure
your mail server to use
opendkim to digitally sign outbound email.
There are a few Debian-specific things you have to care about, though.
First the have to choose a
selector, which is a string used to
distinguish many DKIM keys belonging to the same domain. Debian allows
you to installa a key whose selector is
<something>.<uid>.user,
where
<uid> is your Debian uid (this is done both for namespacing
reasons and for exposing who might be abusing the system). So check
carefully that your selector has this form.
Then you cannot edit directly Debian's DNS record. But you can use the
email-LDAP gateway on
db.debian.org to
install your key in a way similar to how entries in
debian.net are
handled (see the
updated
documentation). Specifically,
suppose that
opendkim-genkey generated the following thing for
selector
vps.gio.user and domain
debian.org:
vps.gio.user._domainkey IN TXT ( "v=DKIM1; h=sha256; k=rsa; "
"p=MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAsM/W/kxtKWT58Eak0cfm/ntvurfbkkvugrG2jfvSMnHHkFyfJ34Xvn/HhQPLwX1QsjhuLV+tW+BQtxY7jxSABCee6nHQRBrpDej1t86ubw3CSrxcg1mzJI5BbL8un0cwYoBtUvhCYAZKarv1W2otCGs43L0sGtEqqtmYN/hIVVm4FcqeYS1cYrZxDsjPzCEocpYBhqHh1MTeUE"
"ddVmPHKZswzvllaWF0mgIXrfDNAE0LiX39aFKWtgvflrYFKiL4hCDnBcP2Mr71TVblfDY0wEdAEbGEJqHR1SxvWyn0UU1ZL4vTcylB/KJuV2gMhznOjbnQ6cjAhr2JYpweTYzz3wIDAQAB" ) ; ----- DKIM key vps.gio.user for debian.org
Then you have to carefully copy the content of the
p= field (without
being fooled by it being split between different strings) and
construct a request of the form:
dkimPubKey: vps.gio.user MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAsM/W/kxtKWT58Eak0cfm/ntvurfbkkvugrG2jfvSMnHHkFyfJ34Xvn/HhQPLwX1QsjhuLV+tW+BQtxY7jxSABCee6nHQRBrpDej1t86ubw3CSrxcg1mzJI5BbL8un0cwYoBtUvhCYAZKarv1W2otCGs43L0sGtEqqtmYN/hIVVm4FcqeYS1cYrZxDsjPzCEocpYBhqHh1MTeUEddVmPHKZswzvllaWF0mgIXrfDNAE0LiX39aFKWtgvflrYFKiL4hCDnBcP2Mr71TVblfDY0wEdAEbGEJqHR1SxvWyn0UU1ZL4vTcylB/KJuV2gMhznOjbnQ6cjAhr2JYpweTYzz3wIDAQAB
and then send it GPG-signed to
changes@db.debian.org:
echo 'dkimPubKey: vps.gio.user blahblahblah' gpg --clearsign mail changes@db.debian.org
Then use
host -t TXT vps.gio.user._domainkey.debian.org to chech the
key gets published (it will probably take some minutes/hours, I don't
know). Once it is published, you can enable DKIM in you mail server
and your email will be signed. Congratulations, you will not look like
a spammer any more!
You can send an email to
check-auth@verifier.port25.com to check
that your setup is correct. They will reply with a report, including
the success of DKIM test.
Notice that currently Debian's setup only allows you to use RSA DKIM
keys and doesn't allow you to set other DKIM fields (but you probably
won't need to set them).
EDIT DSA made an
official announcement about DKIM
support,
which you might want to check out as well, together with its links.
EDIT 2 Now ed25519 keys are supported, the syntax for specifying
keys on LDAP is a little bit more flexible and you can also insert
CNAME records. See the
official
documentation for the updated
details.
So we have solved our problems with spam?
Ha, no! DKIM is only a small step. Useful, also because it enable
other steps to be taken in the future, but small.
In particular, DKIM enables you to say: "This particular email
actually comes from
@debian.org", but doesn't tell anybody what to
do with emails that are not signed. A third-party mail server might
wonder whether
@debian.org emails are actually supposed to be signed
or not.
There is another standard for dealing with that, which is called
DMARD, and I believe that Debian should eventually use it, but not
now: the problem is that currently virtually no email from
@debian.org is signed with DKIM, so if DMARC was enabled other mail
servers would start to nuke all
@debian.org emails, except those
which are already signed, a minority. If people and services sending
emails from
@debian.org will start configuring DKIM on their
servers, which is now possible, it will eventually come a time when
DMARC can be enabled, and spammers will find themselves unable to send
forged
@debian.org emails. We are not there yet, but todays we are a
little step closer than yesterday.
Also, notice that having DKIM on
@debian.org only counters spam
pretending to be from
@debian.org, but there is much more. The
policy on what to
accept is mostly independent on that on what you
send. However, knowing that
@debian.org emails have DKIM and DMARC
would mean that we can set our spam filters to be more aggressive in
general, but whitelist official Debian Developers and services. And
the same can be done for other domains using DKIM and DMARC.
Finally, notice that some incompatibilities between DKIM and mailing
lists are known, and do not have a definitive answer yet. Basically,
most mailing list engines modify either the body of the headers in
forwarded emails, which means that DKIM does not validate any
more. There are many proposed solutions, possibly none completely
satisfying, but since spam is not very satisfying as well, something
will have to be worked out. I wrote a lot already, though, so I wont't
discuss this here.
 I released version 2.5 of ledger2beancount, a ledger to beancount converter.
Here are the changes in 2.5:
I released version 2.5 of ledger2beancount, a ledger to beancount converter.
Here are the changes in 2.5:

 Here is another monthly update covering what I have been doing in the free software world during August 2020 (
Here is another monthly update covering what I have been doing in the free software world during August 2020 (
 DebConf5
This tshirt is 15 years old and from DebConf5. It still looks quite nice!
DebConf5
This tshirt is 15 years old and from DebConf5. It still looks quite nice! 

 Back home then I bought a laptop where one could remove
the harddrive using one screw.
Oh, and then I was foolish during the DebConf5 preparations and said, that I
could imagine setting up a team and doing video recordings, as previous DebConfs
mostly didn't have recordings and the one that had, didn't have releases of them...
And so we did videos. And as we were mostly inexperienced we did them the hard
way: during the day we recorded on tape and then when the talks were done, we
used a postprocessing tool called '
Back home then I bought a laptop where one could remove
the harddrive using one screw.
Oh, and then I was foolish during the DebConf5 preparations and said, that I
could imagine setting up a team and doing video recordings, as previous DebConfs
mostly didn't have recordings and the one that had, didn't have releases of them...
And so we did videos. And as we were mostly inexperienced we did them the hard
way: during the day we recorded on tape and then when the talks were done, we
used a postprocessing tool called '









 Because
Because 




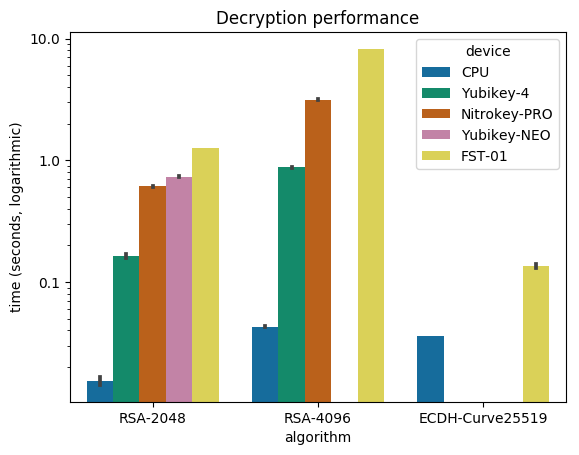
 Debian
devscripts
Before deciding to take an
Debian
devscripts
Before deciding to take an  I was recently asked to sort things out so that
I was recently asked to sort things out so that
{kind=link}
{kind=link}
{kind=link}